pyspark 操作由json创建的hive表报错:AnalysisException: cannot resolve'`xxx`'given input columns: |
您所在的位置:网站首页 › hive translate函数 › pyspark 操作由json创建的hive表报错:AnalysisException: cannot resolve'`xxx`'given input columns: |
pyspark 操作由json创建的hive表报错:AnalysisException: cannot resolve'`xxx`'given input columns:
|
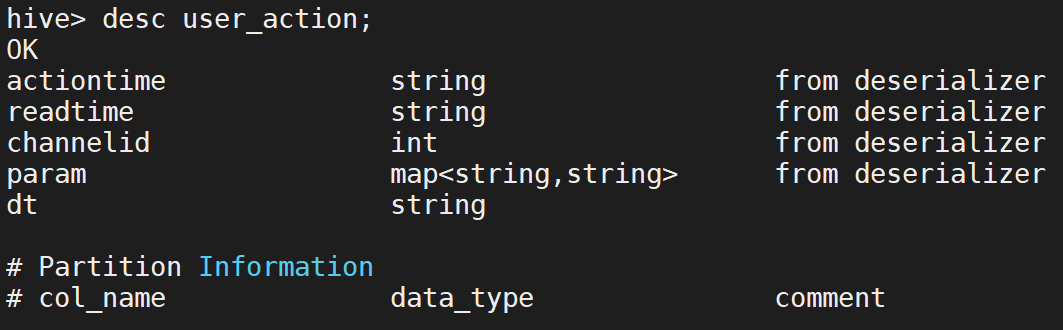
hive中表的结构:
在hive目录下已经创建了auxlib子目录并放入下载的jar包以支持json:
代码,尝试用spark操作由json数据构成的hive表数据: uup.spark.sql('use profile') user_action = uup.spark.sql("select actionTime,readTime,channelId,param.articleId,param['algorithmCombie'] algorithmCombie,param['action'] action,param['userId'] userId from user_action where dt>='2019-04-01'") user_action.show()报错:
原因:hive表如果是由json数据构成的,需要引入hive-hcatalog-core-x.x.x.jar包,这里hive下面已经引入了,所以将代码中的select语句赋值到hive中直接查询是没有问题的。这里的问题是使用spark操作hive的引擎与直接在终端使用hive命令是不一样的,如果直接在终端使用hive命令打开操作hive数据库,hive使用的是hadoop的mapreduce来操作数据。而如果在spark上操作hive数据库,使用的引擎是spark自己的rdd。所以如果操作由json构成的hive表,spark中也应该引入hive-hcatalog-core-x.x.x.jar包。 解决:将hive中的hive-hcatalog-core-x.x.x.jar复制一份到spark中的jars子目录下。
这时重启jupyter服务(只重启jupyter就行,hive、spark都不需要重启),清掉jupyter中的缓冲,再次执行代码:
成功查询到数据! |




【本文地址】
今日新闻 |
推荐新闻 |